

How do I get into Data Science? No doubt that's the most frequent question about the field.
In this article I’ll describe the steps that, in my experience, are the most effective to advance in your career. And of course, the mistakes I’ve made along the way so you don't make them too.
In this first part I’ll cover an overview of four areas: programming, math, data processing and machine learning. Each of these areas can be a specialty on their own, but I will focus on the minimum required to advance to the next step and avoid the overhead, the plan is that at each stage you will keep improving and putting into practice the previous knowledge.
1) Programming:
The best introduction to programming I have found so far is the MIT course: "introduction to computer science", available in EDX and MITOCW. This is a challenging course, the content of a week can take up to 15 hours to complete, but each one worth it. In this class, to solve problems rather than memorizing syntax is the norm and It will require analysis and a good understanding of the content to advance with the assignments. As an example, in the second week of the course, you will implement the bisection method to calculate the payment of a debt with compound interest.
From this course, the material of the first three weeks will be enough to develop an intuition of the Python programming language, including:
- Types of data.
- Functions.
- Tuples, lists and dictionaries.
- Good practices.
Continuing with Python, Raymond Hettinger has an excellent presentation, where he explains how to program in a Pythonic way. In the talk he covers the use of generators, list and dictionary compression, and other matters. These aspects are not essential for programming, but they save many lines and make the code more readable. This presentation includes a summary of spinets for a quick review, an example of this is the below method to concatenate strings:

2) Databases:
This one is a critical aspect and it’s neglected in most data science courses, programs and by many practitioners, I include myself in the former group since during my firsts years of experience I worked almost exclusively on web scraping and natural language processing (NLP). Nonetheless, the knowledge of databases is crucial to advance in the career, and can be a deal breaker. Most companies have their data stored in one of the SQL variants, either On-premise or Cloud, and it will not be possible to access them without knowing the language. There's a lot of material on this subject that can be found, but their main target are web developers, while we are looking for a different approach to get started. With this in mind, I find effective to develop the fundamentals, the following resources:
- The SQLZOO website, which has interactive exercises.
- The free Udacity course SQL for Data Analysis. It has explanations of the most common topics.
- Kaggle Intro to SQL course.
3) Calculus, linear algebra and statistics:
Before getting our hands dirty we need an understanding of the fundamentals upon which the Machine Learning models are built.
On this line, the best explanation I have seen to develop an intuition about linear transformations is the one created and posted by Grant Sanderson, a mathematician from Stanford University, in his Youtube Channel, 3Blue1Brown.
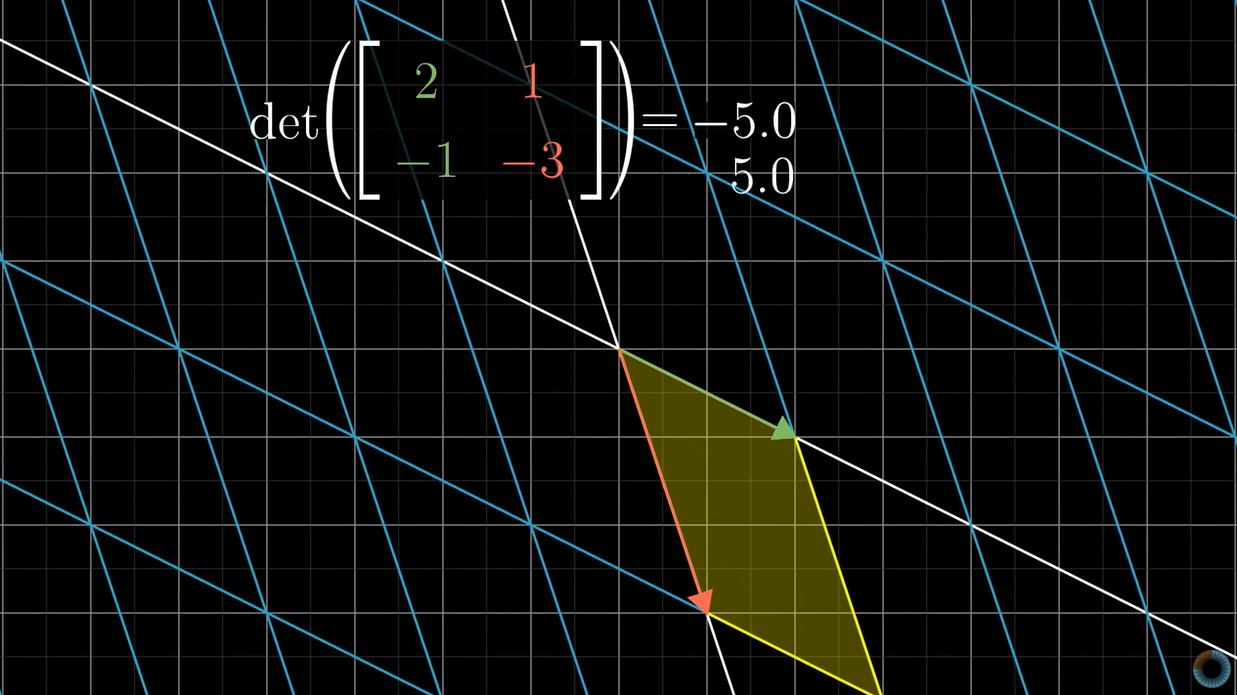
For the folks who prefer to read, in the site betterexplained, Kalid Azad makes a phenomenal job exposing concepts of calculus and statistics. The explanations of Bayes' theorem, the Fourier transform and Euler's formula are just brilliant.
Going deeper into the stats Joshua Starmer, in the Youtube channel StatQuest, presents excellent explanations about topics related to statistics, such as the central value theorem, standard deviation, P-values or principal component analysis.
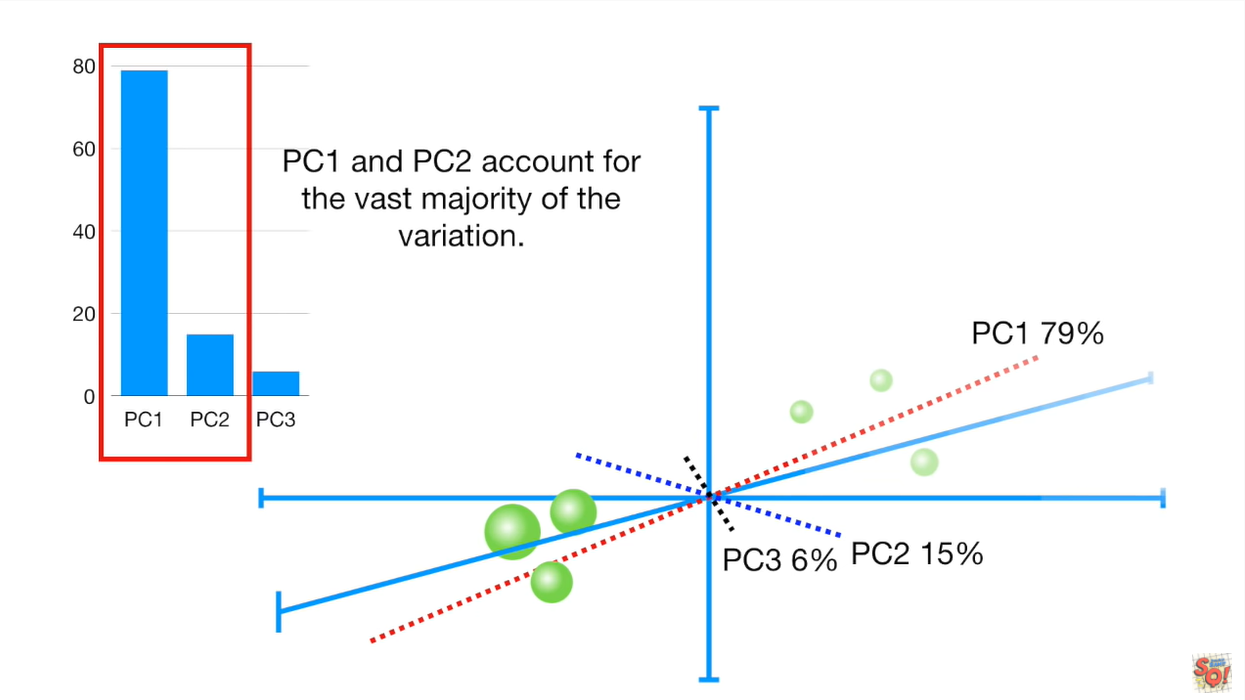
Finally, for a rigorous review of these topics, the linear algebra classes of Gilbert Strang MIT Professor’s are available on YouTube. The book Elements of Statistical Learning is available for free on the Stanford website, and in Udacity, the Linear Algebra Refresher Course covers how to develop a linear algebra library in Python from scratch using numpy.
4) Machine learning:
Once the fundamentals are covered, we are ready to start with the models.
The most popular online course in machine learning is Coursera’s Machine Learning by Andrew Ng, Co-Founder of the platform. It has been online for almost a decade and has over 3 million students enrolled. It is an excellent resource that provides a great balance of mathematical rigor and hands-on experience. On the flip side the material is a bit outdated and it uses Matlab/octave as the main programming tool, which is not that common these days in the job market compared with R and Python.
However, I think, the best introduction to machine learning is the first course of the Machine Learning Specialization by the University of Washington at Coursera. It presents an overview of the machine learning algorithms for regression, classification, recommender systems and image processing, not to mention that the professors Carlos Guestrin and Emily Fox' make an outstanding explanation of the concepts. The rest of the courses in the specialization are a great follow on after the introductions, and are more rigorous and challenging both in coding and math.
The missing piece in this group is deep learning, you may say, but.. we have too much homework already, so you will have to wait for the second part of this series, where we will go into more targeted resources.
5) Continuous Update
Finally, as references to continue advancing in programming, I recommend the Design of computer programs course, taught by Peter Norvig and available for free at Udacity. This is an advanced course where most of the modules are independent and can be revised when necessary. Also, Brett Slatkin's book, “Effective Python: 59 Specific Ways to Write Better Python”, features with a similar approach.
Bonus:
Excel:
What about an estimated of $ 6 million loss? That's a story from JPMorgan Chase Bank caused by errors in a spreadsheet. This is just an example presented by the mathematician and scientific popularizer Matthew Parker on his Youtube channel; just one of many cases where it is evident that the use of spreadsheet certainly increases the chances of corrupting the data. Nevertheless, they are an irreplaceable for quick analysis or presentations due to their interactive nature, and a "must have" to any Data Scientist. Therefore, my recommendations to get familiar with its basic functions are DataCamp y Coursera, both of which count with an interesting variety of courses in this regard.
Let’s go for it
For some readers, it could be overwhelming to get to this point, which is totally normal since we have covered a lot of information throughout the article. However, in my experience, the best way to consolidate the acquired knowledge is to get down to work.
If you are starting from scratch, the best option is to record your progress in a blog explaining topics that you have found interesting or with which you have had problems, such as a short article about the ways to identify duplicate records, or how to use an API. Although these are basic concepts, if they are well illustrated, readers will, for sure, find them useful.
The next step is to create personal projects; these can be an application, a model or the analysis of a data set that interest you. For example, some years ago I wanted to know the job market for Data Scientists in Latin America, and I took it as a personal project. I got the data from the popular Stack Overflow and Kaggle surveys and through web scraping of job posting sites; Once the work was done, I published a post on Medium with my conclusions.
Practice makes the master, and what’s a better way to practice than to learn and get paid for it? This can be done by applying to basic jobs though platforms as Upwork or even Fiverr, and although in the medium term the goal is to get advanced jobs, before that, it is essential to gain experience and Freelance jobs are a great way to do it. Some of the simplest tasks you can start with are: data cleaning, web scraping and dashboard creation.
Finally, it is crucial to keep in mind that this will be a competitive and challenging career. The speed with which you advance will largely depend on previous knowledge and, even after you have covered the basics, you should spend time just to keep up with developments in the area. Still, it is an excellent career that will allow you to work in a variety of interesting industries and projects.
Resources
Programming
- EDX MIT 6.00X
- Idiomatic Python: Video, Snipets
- Design of computer programs
- Effective Python
Comments